The rapid advancement of large language models (LLMs), exemplified by GPT-3.5 and LLaMA 3, has precipitated a
transformative shift in artificial intelligence (AI), yielding state-of-the-art performance across diverse tasks.
Specifically, these tasks include content generation, natural language understanding, and complex decision-making, all
of which have been revolutionized by the extensive pretraining and sophisticated architectures of LLMs. Notably, the
introduction of frameworks like Chain-of-Thought (CoT) has further expanded LLM's capacity for multi-step reasoning,
enabling them to tackle more intricate tasks.
Despite these advancements, ensuring the reliability and accuracy of model outputs, especially for reasoning-intensive
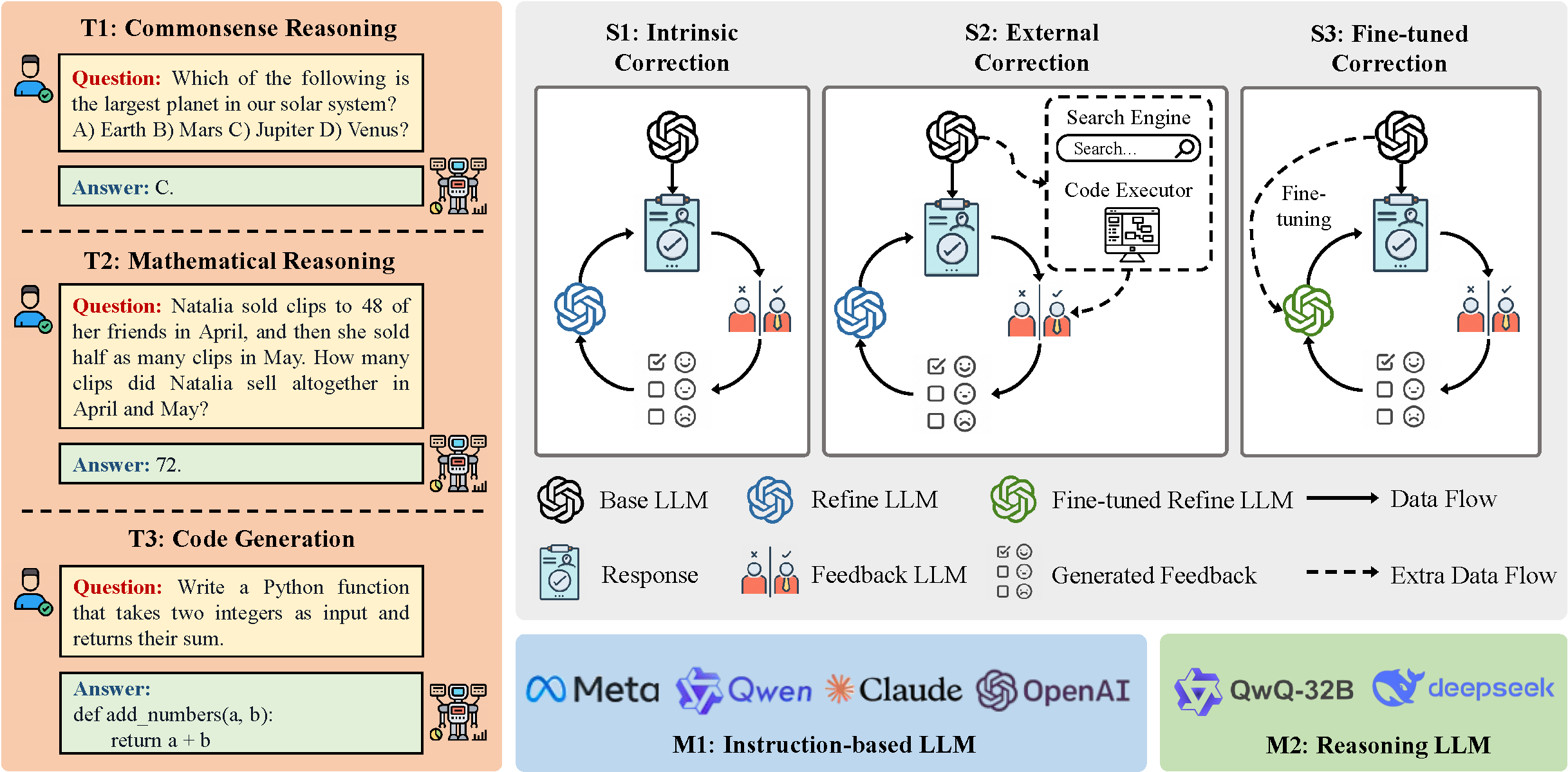
tasks, remains a formidable challenge. In response, recent works have focused on self-correction strategies aimed at
refining LLMs' decision-making processes through iterative revision. Pioneering approaches such as RARR, Refiner, and
CRITIC illustrate the potential of integrating feedback loops and corrective components into model architectures.
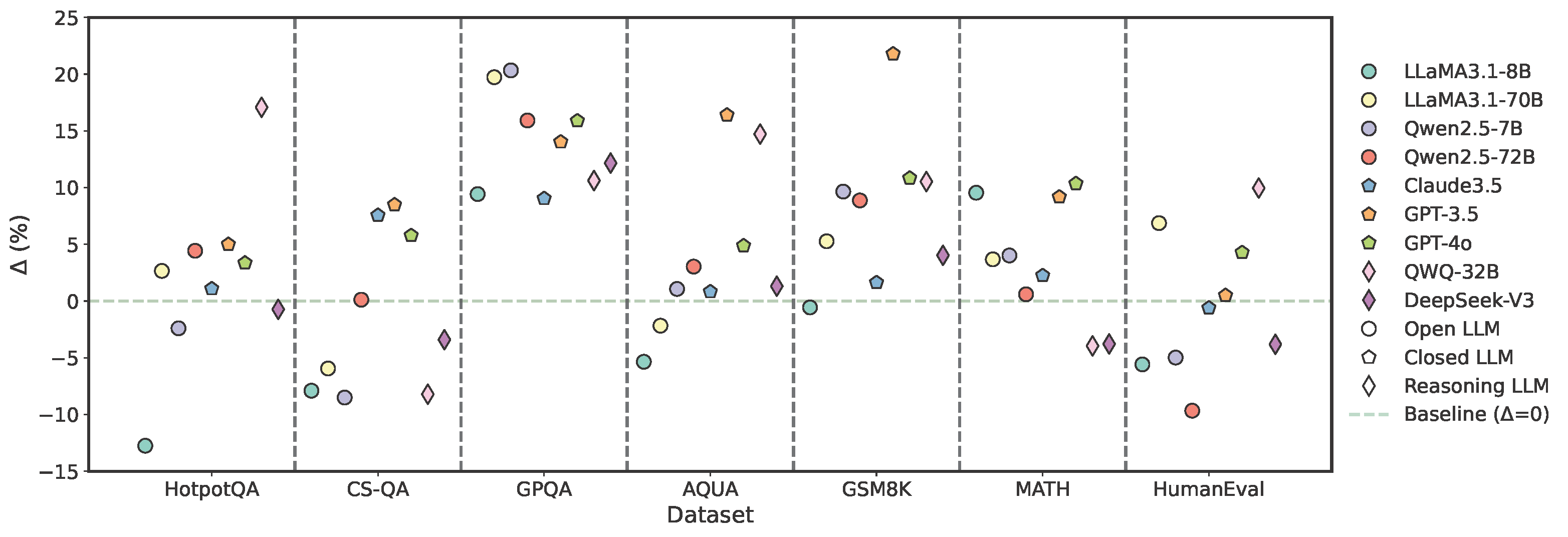
However, these approaches often yield inconsistent gains across different tasks, prompting deeper questions about their
capability of correction and generalizability.